En los últimos años, los LLM (large language model) han experimentado un crecimiento exponencial desde que OpenAI los situó en el foco. Gracias a sus capacidades de procesamiento y generación de lenguaje natural tenemos a nuestro alcance herramientas como ChatGPT que están revolucionando el mundo digital acelerando procesos de generación de contenidos, marketing o desarrollo. Este tipo de usos son llevados a cabo por los profesionales que hay detrás de los sitios web pero ¿Pueden ser de interés para el usuario final de una web?
Una de las técnicas más importantes que nos permite personalizar la experiencia que tiene el cliente en nuestro ecommerce es la conocida como Retrieval-Augmented Generation (RAG), que combina la generación de texto con la recuperación de información en tiempo real, permitiendo ofrecer respuestas más precisas y contextualizadas ya que en la mayoría de casos nos enfrentaremos al problema que supone que el LLM no disponga de información específica de nuestro catálogo en el momento de su entrenamiento y por tanto no puede responder adecuadamente y sin alucinar al no tener la información adecuada.
Soluciones inteligentes con RAG
Gracias a las nuevas funcionalidades que posibilita esta tecnología podemos mejorar la tasa de conversión de nuestra tienda online desde otro ángulo. Por ejemplo proporcionando recomendaciones más acertadas, respuestas automáticas personalizadas y contenidos dinámicos que se adaptan a las necesidades específicas de cada cliente. Algunas propuestas que podrían implementarse haciendo uso de RAG:
- Asistente de compra: Una tienda de ropa en la que al navegar entre camisas puedas escribir tu propio filtro «Necesito que combine con un unas bermudas beige».
- Banners personalizados: En función de los últimos productos vistos se puede personalizar parte del contenido. Tras navegar por una serie de productos de un estilo formal se pueden generar descripciones cortas como «La camisa perfecta para un evento formal.».
- Asistente de condiciones de compra: Podemos crear un buscador avanzado para nuestras condiciones de compra.
- Bonus: Hemos hablado de aplicaciones enfocadas en nuestro usuario final pero y si utilizando las mismas técnicas el sistema nos pudiera resumir y priorizar el estado de las incidencias para resolver las más importantes primero?
RAG paso a paso
El proceso de Retrieval-Augmented Generation (RAG) sigue una serie de pasos característicos para combinar la recuperación de información con la generación de texto:
- Se procesa la consulta recibida como entrada: Se pueden eliminar palabras carentes de significado, extraer las más importantes o generar embeddings de la consulta.
- Se realiza la fase de retrieval (recuperación): El sistema busca en una base de datos o en un conjunto de documentos relevantes para encontrar información relacionada con la consulta. En este paso se puede agregar información de diferentes fuentes como la BD de la plataforma, o una BD vectorial que nos permita encontrar los documentos que tengan mayor similitud con la consulta.
- Generación aumentada de texto: En la fase de augmented generation el LLM usa tanto una consulta base enriquecida con la información recuperada para generar una respuesta coherente pero que a la vez integre la información obtenida en la fase de retrieval que aporta un contexto concreto.
- Finalmente se entrega al usuario la respuesta personalizada que optimiza la precisión y relevancia de la respuesta dado que ha utilizado además de la información del propio LLM los datos específicos relevantes para la consulta.
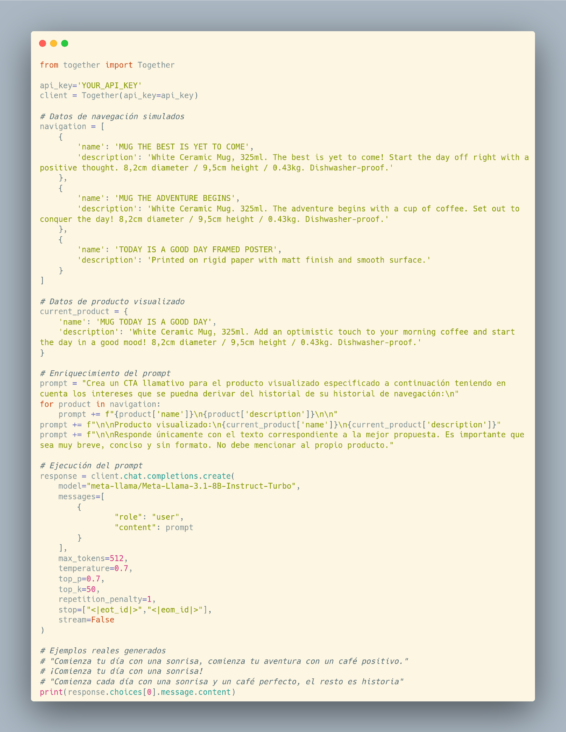
Ejemplo real: Banners personalizados
- Recuperamos la información de los productos en el historial de navegación reciente y el producto que se está visualizando
- Generamos un prompt agregando toda la información obtenida en el punto 1.
- Ejecutamos el prompt para generar un texto personalizado.
Implementación en menos de 50 líneas
En el código de ejemplo usaremos el servicio de Together AI para ejecutar nuestro modelo y simplificaremos la obtención de los datos de navegación y de producto con datos simulados, dependiendo de nuestra plataforma la implementación variaría ligeramente.
Ejemplo real: Asistente de condiciones de compra
En este caso utilizaremos una BD vectorial en la que almacenaremos los embeddings generados de todos los documentos de condiciones de compra.
Por tanto primero necesitaremos poblar la BD con toda nuestra base de conocimiento:
- Preprocesar los contenidos para ignorar partes no relevantes. Por ejemplo eliminando todas las etiquetas HTML.
- Dividir los documentos en bloques de tamaño adecuado.
- Generar los embeddings y almacenarlos.
Con esta información preparada el usuario podrá realizar consultas:
- Obtener los fragmentos más relevantes para la consulta del usuario mediante una búsqueda en la BD vectorial.
- Recuperar los documentos completos correspondientes a los fragmentos.
- Enriquecer el prompt que ejecutaremos con el LLM usando el contenido de los documentos recuperados en el paso 2.
- Devolver la respuesta del LLM al usuario final.
En esta ocasión se puede usar un prompt similar al siguiente:

Conclusiones
Como hemos visto se trata de una técnica cuya barrera de entrada ha disminuido mucho con el crecimiento de los LLM y que nos permite implementar funcionalidades que hasta ahora eran complejas, costosas o inviables con las tecnologías clásicas. Además entre las ventajas de su uso frente al uso de un LLM directamente se encuentran la reducción de las alucinaciones, la mejora de la exactitud de las respuestas y la posibilidad de trabajar con LLMs e información específica sin entrar en opciones más complejas como entrenar nuestro propio modelo. A la vez cuenta con algunas desventajas, entre las más notables podemos encontrar el aumento de latencias si comparamos con una simple búsqueda en una BD, también debemos disponer de la información necesaria de forma suficientemente organizada como para poder tratarla en los pasos correspondientes y por último el hecho la imposibilidad de evitar completamente las alucinaciones o inconsistencias entre el texto generado y los documentos originales.